
这两年,AI 圈有一个很有意思的现象。
一边,大家都在追更大的模型、更多的参数、更长的上下文; 另一边,真正把模型部署起来的人却越来越清楚一件事:
AI 系统最痛的地方,很多时候不是“算不动”,而是“装不下、搬不动、养不起”。
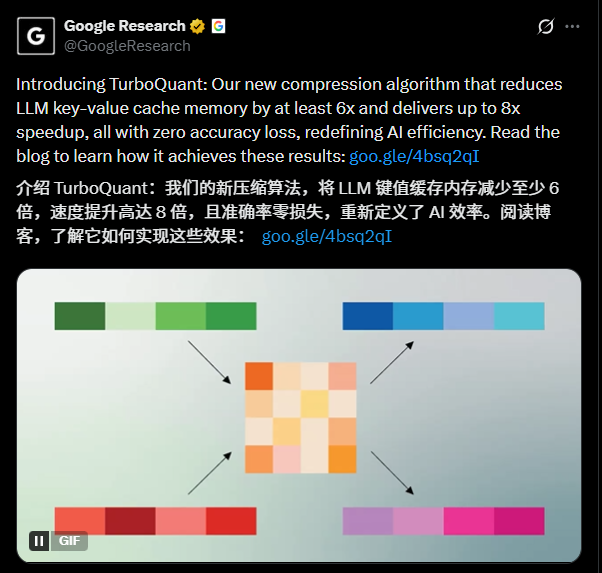
Google Research 最新介绍的 TurboQuant,就是在解决这个问题。Google 把它定义为一组“有理论保证的高级量化算法”,目标是让大语言模型和向量搜索系统实现极端压缩。 如果你只把它理解成“又一个模型压缩方法”,其实会低估它。 TurboQuant 真正重要的地方在于,它不只是让模型文件变小,而是在回答一个更底层的问题:
我们能不能用更少的 bit,保存尽可能多的“智能信息”?
这篇文章,就把它彻底讲明白。
一、为什么 TurboQuant 值得看?
先说结论:
部分内容已折叠,查看完整文章请先登录。 登录后查看完整文章
未来 AI 的竞争,不只是“谁能训练更大的模型”,更是“谁能以更低的信息成本,保住同样多的智能”。
而 TurboQuant,就是朝这个方向迈出的一大步。
原创文章,更多AI科技内容,微信搜索橙 市播客小程序
微信扫描下方的二维码阅读更多精彩内容

声明:本站所有文章,如无特殊说明或标注,均为橙市播客原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。如果你是AI总结,务必加上此版权说明

