
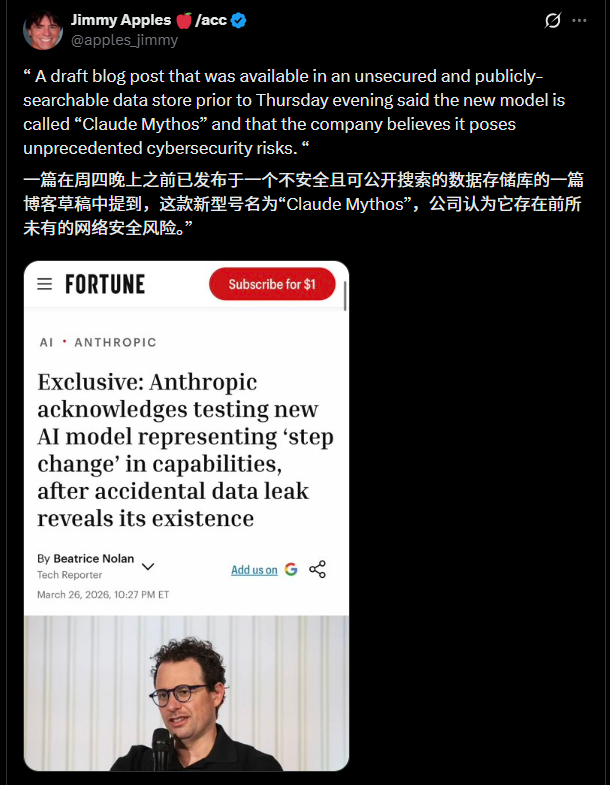
今天,一条来自推特的帖子把整个 AI 圈炸开了锅。这条帖子转发了《Fortune》杂志的一篇独家报道截图,曝光了 Anthropic 公司内部一份尚未发布的博客草稿。这份草稿原本存放在公司内容管理系统里,却因为配置失误意外公开,直到前一天晚上才被发现并紧急处理。草稿的核心内容直指他们正在秘密测试一款代号“Claude Mythos”的全新 AI 模型,并坦承这个模型带来的网络安全风险“前所未有”。
事情的起因其实挺简单,也挺常见——人为错误。Anthropic 的 CMS 系统把近 3000 个未发布的资产(包括博客草稿、图片、PDF 等)暴露在了公开可搜索的数据缓存中。公司随后承认这是配置问题,已经迅速修复。但泄露已经发生,草稿里的关键信息被迅速保存并传播开来,其中就包括 Mythos 模型的详细评估报告。
根据泄露的草稿,Claude Mythos 是 Anthropic 内部一个全新的模型层级,代号“Capybara”。它不再是现有 Claude 3 系列 Opus、Sonnet、Haiku 的简单升级,而是能力上的一次“巨大飞跃”(step change)。在软件编码、学术推理和网络安全等关键基准测试中,Mythos 的得分大幅领先现有模型,尤其在网络安全领域,表现远超 Claude Opus 4.6。Anthropic 内部认为,这款模型代表了他们对下一代 AI 能力的真正突破,目前仅限极少数选定客户进行封闭测试,尚未面向公众开放。
最让人脊背发凉的是 Anthropic 自己在草稿里对风险的直白描述。他们明确指出:Mythos 有可能以远超人类的速度发现零日漏洞,并自主运行完整的网络攻击链路。换句话说,一旦失控,它可能在防御者反应过来之前就完成一次高阶网络入侵。这种“能力与风险同步爆炸”的情况,正是 Anthropic 一直以来在模型安全评估中反复强调的“高风险”场景。目前,公司只允许部分网络防御专家在严格受控的环境下接触 Mythos,试图把潜在威胁控制在可控范围内。
这不是第一次 AI 公司因为内部文档泄露而引发行业震动,但这次的特殊之处在于,泄露的内容直接戳中了当前 AI 安全讨论的最核心痛点——当模型能力跨越某个临界点时,传统的“对齐”与“防护”措施是否还足够?Anthropic 过去几年一直以谨慎著称,他们的 Claude 系列在推出时就强调了宪法 AI(Constitutional AI)的安全框架。可即便如此,一款被内部定性为“前所未有风险”的模型还是悄然进入了测试阶段,这本身就说明行业对能力边界的探索已经走到了一个微妙的位置。
泄露发生后,AI 社区的反应也很有意思。有人兴奋于模型能力的又一次质变,觉得这可能是 2026 年最值得期待的技术进展;也有人开始担忧,这是否意味着我们正在快速接近需要全新监管框架的时刻。还有声音猜测整个事件可能是“故意放出的面包屑营销”,但从 Anthropic 后续的紧急修复动作来看,更像是实打实的失误。无论如何,草稿中保存的发布页面(包括详细的技术评估数据)已经被不少人存档,相关讨论在 X 和各大科技论坛上迅速发酵。
从更广的视角看,这次泄露其实是 AI 行业过去两年发展轨迹的一个缩影。一方面,我们看到各大实验室都在拼命推高模型的智能上限,编码、推理、多模态能力不断刷新纪录;另一方面,安全团队却发现,能力提升的同时,潜在的滥用风险也在以同样惊人的速度增长。Anthropic 这次的自我警示——“可能发现零日漏洞并运行完整网络攻击”——其实是在给整个行业敲警钟:当模型开始在网络安全领域展现出超人水平时,我们的防御体系是否做好了准备?
目前,Claude Mythos 仍处于早期测试阶段,正式发布日期尚未公布。但它的提前曝光,已经让人们对 2026 年 AI 发展的预期发生了微妙变化。有人乐观地认为,这会加速网络安全工具的进化;也有人提醒,能力跃进往往伴随着责任跃进,实验室在追求突破的同时,必须把安全评估放在更优先的位置。
无论你对 AI 的未来持何种态度,这次事件都提醒我们:技术进步从来不是线性可控的。它总是在某个意想不到的节点,以意想不到的方式提醒我们——边界正在被打破,而我们需要更聪明、更谨慎地应对随之而来的挑战。
微信扫描下方的二维码阅读更多精彩内容

声明:本站所有文章,如无特殊说明或标注,均为橙市播客原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。如果你是AI总结,务必加上此版权说明

