

刚刚,DeepSeek官方突然发布了DeepSeek-V4,让不少关注开源大模型的人眼睛一亮。DeepSeek这次没玩虚的,直接把Preview版本推出来,还同步开源了权重。核心卖点就一个:把百万token(1M)上下文长度真正做到了实用级别,而且成本还控制得不错。
从宣布上线开始,逐一拆解了两个新模型、性能亮点、架构创新和实际使用方式。读下来感觉他们这次是真的在长上下文这块下狠功夫了,不再是纸面参数堆砌,而是想让开发者真正用得爽。
先说模型本身。DeepSeek-V4 Preview推出了两个变体,都是Mixture-of-Experts(MoE)架构,这套路DeepSeek从V2、V3一路玩下来,已经很熟练了。
-
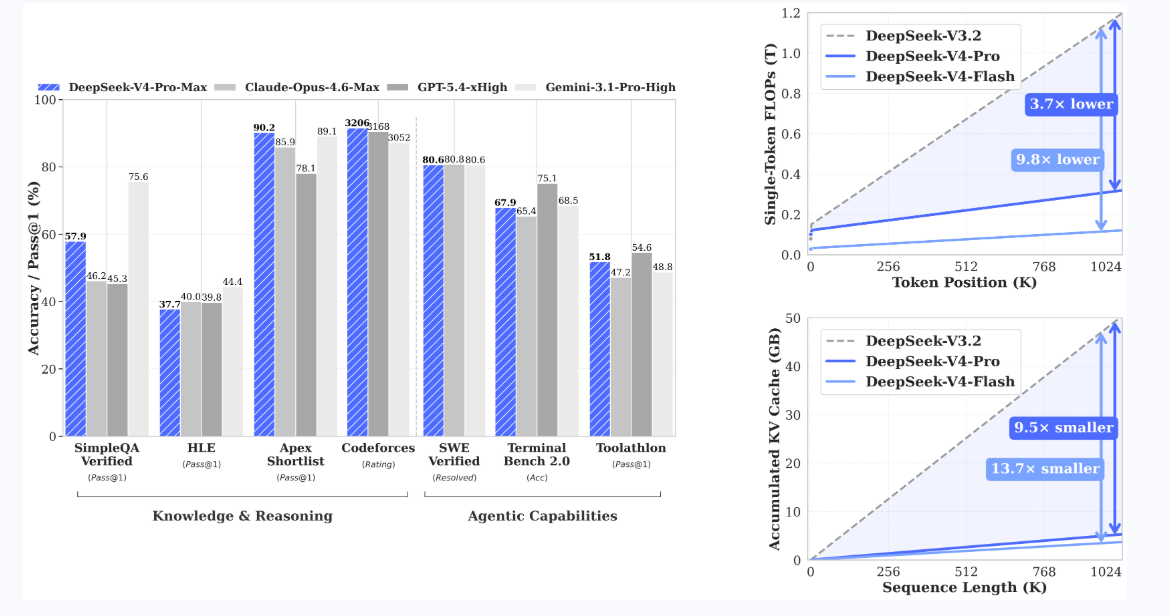
DeepSeek-V4-Pro:总参数1.6万亿(1.6T),但激活参数只有49B。听起来吓人,但MoE的精髓就是只激活一部分专家,所以实际推理开销没那么离谱。他们说这个版本在Agentic Coding(代理式编程)基准上达到了开源SOTA,世界知识储备在所有开源模型里排前列,仅次于Gemini-3.1-Pro之类的闭源顶尖选手。在数学、STEM、编码这些硬核领域,推理能力已经能和顶级闭源模型掰手腕。
-
DeepSeek-V4-Flash:总参数284B,激活参数13B。定位更轻快,推理速度更快,API价格也更亲民。简单Agent任务上表现和Pro版差不多,适合日常高频使用或者预算有限的场景。
两个版本都原生支持1M上下文长度,这点是这次升级的最大亮点。以前V3系列最高128K,用着用着就觉得不够,尤其是处理整本代码仓库、长文档分析或者多轮复杂对话的时候。现在直接跳到百万级别,相当于能一次性塞进去几千页文本或者整个大型项目代码。
他们还特别强调了上下文效率的提升。新引入的注意力机制包括Token-wise compression(逐token压缩)和DSA(DeepSeek Sparse Attention,稀疏注意力)。在1M上下文下,计算量和内存占用比前代大幅下降。据他们自己的技术报告,在长上下文场景中,单token推理FLOPs只需要之前的27%,KV Cache内存更是降到10%左右。这意味着你不用再为长输入烧光显存或者等半天出结果,实际可用性上了一个台阶。
Agent能力是另一个重点优化方向。V4-Pro在复杂代理任务上表现突出,已经能和Claude Code、OpenCode之类的工具链无缝对接。DeepSeek自己内部也在用它做Agentic Coding,线程里还放了用V4-Pro生成的PDF示例,看起来排版和内容组织都挺自然。Flash版虽然轻一些,但在简单Agent场景里和Pro版差距不大,性价比拉满。
使用上挺方便。聊天界面那边有Expert Mode和Instant Mode可选,API当天就更新了。调用时不用改base_url,只要把模型名换成deepseek-v4-pro或者deepseek-v4-flash就行。支持OpenAI的ChatCompletions格式,也兼容Anthropic的API风格。两个版本都带Thinking / Non-Thinking双模式,前者适合需要深度推理的场景,后者更快。
值得注意的一点是,旧模型deepseek-chat和deepseek-reasoner会在2026年7月24日正式退役,现在已经路由到V4-Flash的对应模式了。建议手里还在用旧ID的开发者尽快迁移。
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
DeepSeek-V4 技术报告:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
微信扫描下方的二维码阅读更多精彩内容

声明:本站所有文章,如无特殊说明或标注,均为橙市播客原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。如果你是AI总结,务必加上此版权说明
