
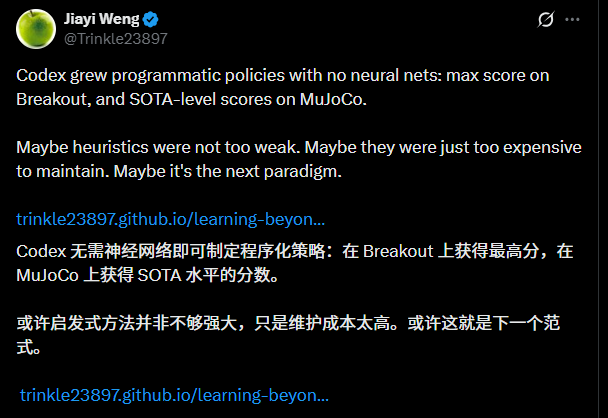

最近看到OpenAI研究员Jiayi Weng的一篇帖子,里面讲的东西让我挺兴奋的。他没有训练什么新神经网络,而是让LLM编码代理去迭代纯Python代码,结果在Atari Breakout上直接打出了理论最高分864,还在MuJoCo、VizDoom等环境里拿到接近或超过当时Deep RL的水平。这不是炫技,而是把一个老想法重新激活了--启发式学习(Heuristic Learning,简称HL)。
事情是怎么开始的
Jiayi在维护EnvPool这个并行环境库的时候,想找些便宜又好复现的策略来快速验证环境是否正常。神经网络每次都要训半天,太贵了。于是他试着让Codex(当时叫gpt-5.4)去写和改纯代码策略。
没想到,事情越搞越离谱。
在Atari Breakout里,初始策略大概只有387分,简单到“球在左边我就往左移”。几轮迭代之后,代码里开始出现球和挡板的检测、着陆点预测、卡住循环处理、动作探测、回归测试、视频回放、实验日志……最后分数一路冲到864,也就是理论最高分。
更夸张的是MuJoCo HalfCheetah,5个episode平均分达到了11836.7,属于SOTA级别;Ant也从基础步态进化到带短期规划,轻松过6000分。VizDoom这种第一人称视觉任务,用纯cv2+NumPy也打出了均值557的成绩。
最关键的不是分数,而是他根本没训神经网络。他在维护一个不断生长的软件系统。
什么是Heuristic Learning(HL)
简单说,HL就是把“要优化的对象”从神经网络参数,换成了代码、规则、状态机、控制器、MPC、宏动作这些软件结构。
这个工作,就是一个很好的例子。
你怎么看?欢迎评论区讨论。
更多AI科技内容,微信搜索橙市播客小程序
微信扫描下方的二维码阅读更多精彩内容

声明:本站所有文章,如无特殊说明或标注,均为橙市播客原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。如果你是AI总结,务必加上此版权说明

