
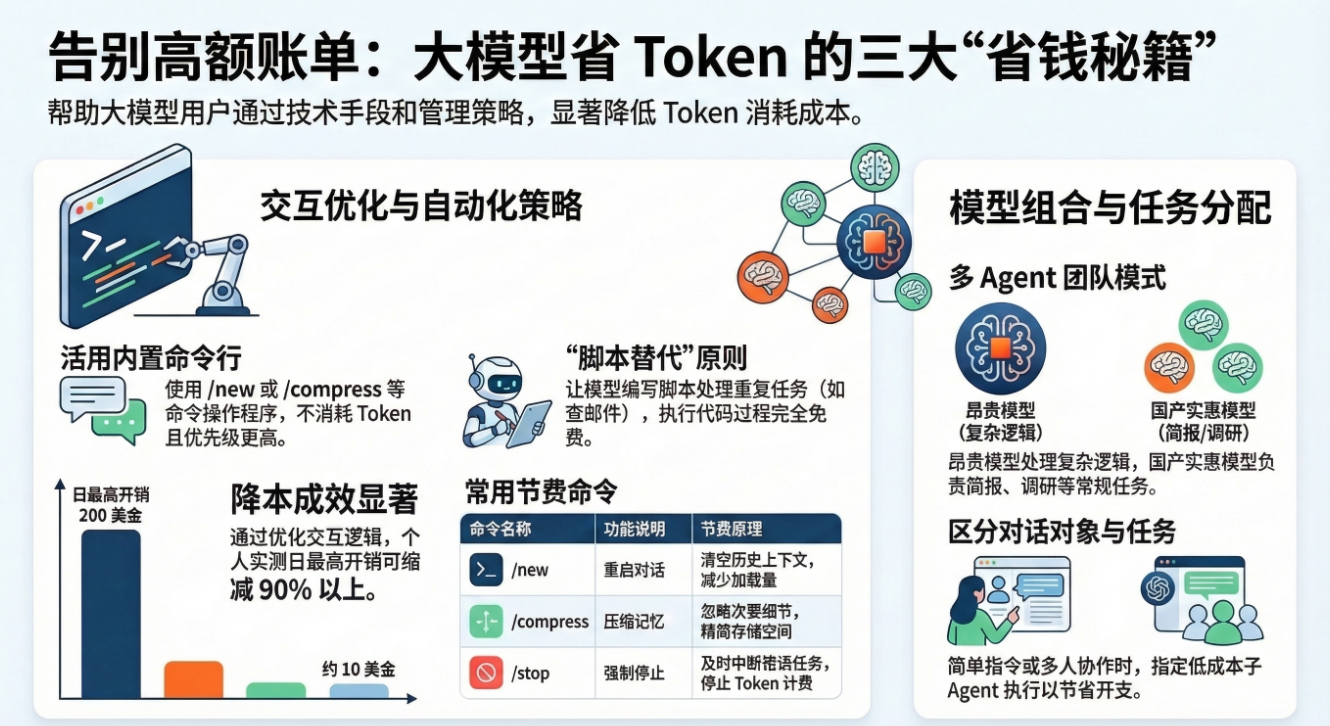
在AI大模型应用日益普及的当下,“养龙虾”(使用大模型)的Token成本问题让不少用户直呼“吃不消”。有的小伙伴仅仅和大模型打个招呼,几元钱就悄无声息地花出去了。不过别担心,今天就为大家带来三大省Token技巧,助你大幅降低“养龙虾”的成本。我自己就从一天花费200多美金,降到了几十美金,甚至有时仅需10美金左右。
技巧一:善用命令行,绕开大模型直接交互
大模型在设计时,内置了几个特殊的命令行。这些命令行不经过大模型,直接与驻留在电脑上的程序交互,本身不消耗任何Token,而且优先级高于大模型。
/new命令:用于重启一个对话,清空之前的对话历史上下文。这样大模型就不用加载大量历史记忆,只需明确当前主人和任务,能有效节省Token。/restart命令:可以直接重启整个大模型程序。当你不知道大模型在忙什么,或者仅仅因为一句“你好”就消耗了大量上下文时,这个命令能让大模型只加载USER.md和SOUL.md,从而大量节约Token。/stop命令:当你给大模型布置了一个长任务,它却想错了方向,此时使用/stop,它会停下手头任务来响应,从而省下原本要花费的Token。/compress命令:大模型的记忆存储在MEMORY.md中,随着使用会越来越庞大。使用/compress,大模型会自动帮你压缩记忆,保留重要信息,忽略次要细节,以此减少Token消耗。
技巧二:能用程序搞定的,别让大模型来
有时候给大模型布置任务,它会噼里啪啦想一堆,自言自语间Token就被大量消耗。应对这种情况,最好的办法是让大模型把任务写成脚本,后续用脚本执行,代码不行再让大模型上,因为代码执行不消耗Token。
以检查邮件为例,我曾因为让大模型每5分钟检查一次邮件,消耗了大量Token。后来我让大模型生成检查邮件的脚本,只有脚本发现新邮件时,大模型才介入处理。这样一来,重复的检查任务由脚本完成,大大节省了Token。
对于类似看新闻简报等重复任务,都可以采用这种思路,先和大模型商量如何用脚本实现,从而减少大模型的不必要消耗。
技巧三:用好不同版本大模型,各司其职
部分内容已折叠,查看完整文章请先登录。 登录后查看完整文章
- 多agent团队模式:将一个大模型变成多agent团队,不同agent负责不同类型的任务。比如复杂的代码编写任务交给昂贵的海外大模型,而整理简报、做调研、生成PDF文档等任务交给便宜的国产大模型。
- 区分对话对象:如果有多人使用大模型,除了自己用顶级模型外,同事可以用便宜又好用的模型。因为对于收集建议这类任务,只需如实传达命令即可,不需要高成本的模型。
- 启动子agent指定模型:当配置多agent麻烦时,可以针对某一个具体任务,直接指定使用的模型。例如要生成一份关于315主题晚会的简报,就启动一个子agent并指定用合适的国产模型来完成。
通过以上三大技巧,我们可以在“养龙虾”的过程中,大幅降低Token消耗,让大模型的使用更加经济高效。
原创文章,更多AI科技内容,微信搜索橙市播客 小程序
微信扫描下方的二维码阅读更多精彩内容

声明:本站所有文章,如无特殊说明或标注,均为橙市播客原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。如果你是AI总结,务必加上此版权说明

