
在大语言模型(LLMs)向“智能体”演进的过程中,推理阶段的计算需求正成为核心瓶颈--尤其是处理长序列轨迹、工具交互或复杂决策时,传统全注意力机制的二次时间复杂度与线性增长的键值(KV)缓存,会带来巨大的计算与内存开销。为解决这一问题,Moonshot AI团队提出了Kimi Linear混合线性注意力架构,首次在短上下文、长上下文及强化学习(RL)场景中,实现了对全注意力模型的性能超越,同时大幅提升效率。
一、核心痛点:全注意力与线性注意力的“两难困境”
在深入Kimi Linear之前,需先理解当前注意力机制的核心矛盾:
- 全注意力(如Transformer的Softmax Attention):能捕捉全局信息,表现力强,但计算复杂度随序列长度(T)呈$O(T^2)$增长--若处理100万token的长文档,计算量会是1万token的10000倍,且KV缓存需存储所有token的键和值,内存占用极高。
- 传统线性注意力(如Linear Attention):通过“键值对累积”将复杂度降至$O(T)$,但因内存管理粗糙(如仅用单一遗忘率),表现力远逊于全注意力,甚至在短序列任务中都难以达标。
举例来说:若用全注意力处理一本1000页的小说(约50万token),GPU可能因KV缓存不足而崩溃;若换传统线性注意力,虽能运行,但会因“遗忘过多关键信息”,无法准确回答“第10页提到的人物在第500页的结局”这类跨章节问题。Kimi Linear的核心目标,就是打破这种“效率与性能不可兼得”的困境。
二、核心创新:Kimi Delta Attention(KDA)的“细粒度记忆管理”
Kimi Linear的基石是Kimi Delta Attention(KDA)--一种优化后的线性注意力模块,通过“细粒度门控”与“硬件友好的分块算法”,解决了传统线性注意力的“记忆混乱”与“计算低效”问题。
1. 从“粗放遗忘”到“精准调控”:细粒度门控机制
传统线性注意力(如Gated DeltaNet,GDN)采用“头级标量遗忘门”--一个注意力头下的所有特征维度,共享同一个“遗忘速率”(类似用一个开关控制所有房间的灯光)。这种设计会导致“该忘的没忘,该留的被删”:比如处理对话时,可能误删用户的核心需求,却保留了无关的语气词。
Kimi Linear的突破并非“单点优化”,而是通过“细粒度门控+混合架构+硬件优化”的组合拳,解决了长期困扰LLM的“效率-性能”矛盾:
- 技术层面:首次证明线性注意力架构可超越全注意力,打破“线性注意力只能做效率补充”的认知;
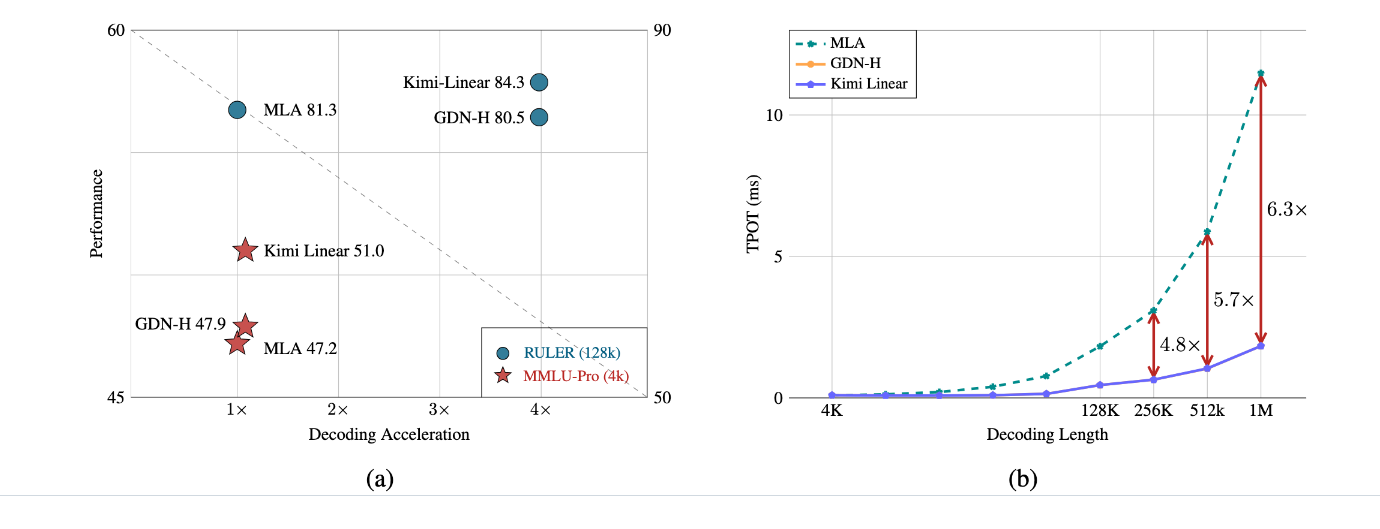
- 实用层面:100万token上下文下,KV缓存省75%、解码快6倍,可直接应用于长文档分析、代码仓库管理、AI智能体交互等场景;
- 生态层面:开源资源降低了混合注意力的研究门槛,为更多开发者提供“高效LLM”的解决方案。
随着5.7万亿token扩展训练的完成,Kimi Linear在100万token的RULER任务中得94.8分,进一步验证了其在超长长序列场景的优势。可以预见,这种“高效且高性能”的注意力架构,将成为下一代大语言模型的核心组件,推动LLM向“更长上下文、更低成本、更强能力”的方向演进。
github:https://github.com/MoonshotAI/Kimi-Linear 技术报告:https://github.com/MoonshotAI/Kimi-Linear/blob/master/tech_report.pdf huggingface:https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
微信扫描下方的二维码阅读更多精彩内容

声明:本站所有文章,如无特殊说明或标注,均为橙市播客原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。如果你是AI总结,务必加上此版权说明

