
OpenAI 扔出了一条挺硬核的公告,和 AMD、Broadcom、Intel、Microsoft、NVIDIA 这些老牌玩家一起,搞出了一个叫 MRC(Multipath Reliable Connection,多路径可靠连接)的网络协议,还直接通过 Open Compute Project 开源了。
这玩意儿不是什么花里胡哨的新模型,而是专门给大规模 AI 训练集群量身定做的网络方案。说白了,就是想解决数万甚至十几万张 GPU 一起干活时,那种让人抓狂的同步和可靠性问题。
大规模训练最头疼的其实是网络
大家聊 AI 进步的时候,总爱说参数量、芯片数量、算力堆叠。但真正跑到生产环境里,你会发现:把这么多 GPU 绑在一起高效干活,网络才是最容易拖后腿的那一个。
在训练一个前沿大模型的时候,每一步(step)都需要所有 GPU 之间频繁交换海量数据。只要有一次传输卡顿或者丢包,整个集群就得等着--因为同步训练的特性,所有卡都得步调一致。结果就是:明明买了天价的 GPU,却有不少时间在干瞪眼。
更麻烦的是,集群规模越大,网络故障就越常见。传统网络协议在这种极端规模下,恢复时间动辄几秒甚至更长,训练作业可能直接中断或者大幅降速。OpenAI 自己跑着全球顶尖的超级计算机,显然是被这些问题反复教育过了。
MRC 到底做了什么?
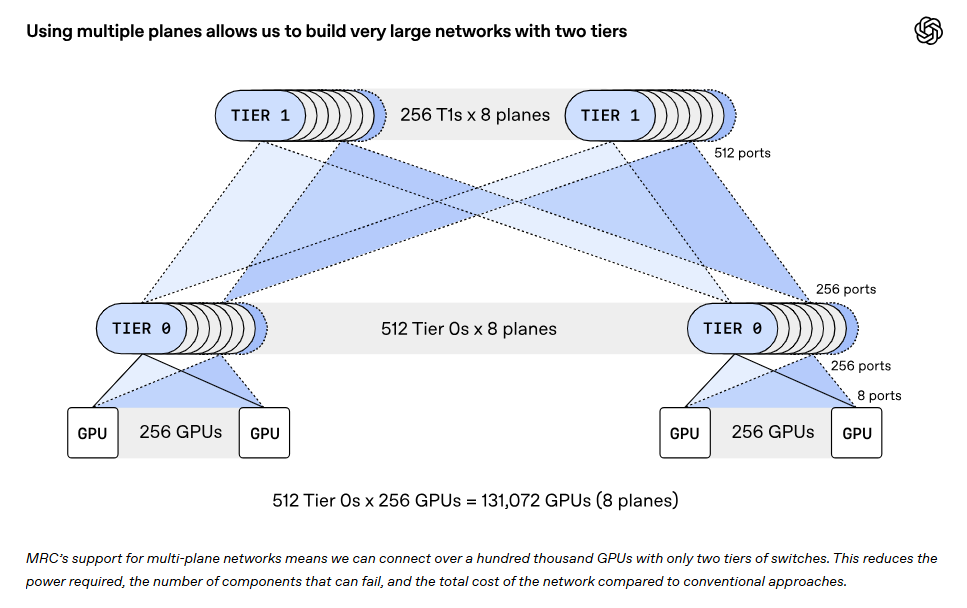 MRC 的核心思路可以简单概括为:把路修多条、把车分多条走、出了问题也能快速绕。
MRC 的核心思路可以简单概括为:把路修多条、把车分多条走、出了问题也能快速绕。
具体有几个关键设计:
感兴趣的同学可以去 OpenAI 的博客看完整技术细节,还有动画和真实训练数据图。开源规格已经在 OCP 上,大家有条件的话也可以去研究研究--说不定下一个大优化就来自社区。
AI 的竞赛,正在从台前模型参数的比拼,越来越深入到幕后这些看不见的基础设施里。而这一次,OpenAI 选择把幕后的东西摆到了台面上。
原创文章,更多AI科技内容,微信搜索橙市播客小程序
微信扫描下方的二维码阅读更多精彩内容

声明:本站所有文章,如无特殊说明或标注,均为橙市播客原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。如果你是AI总结,务必加上此版权说明

